Agent Skills are an API Design Problem, not a Documentation Problem
300k tokens, 35+ skills, 3.000+ assertions. The patterns that survived.


Everyone writes agent skills like documentation. Long instructions, detailed examples, comprehensive reference material. Then they wonder why the skill never triggers.
Skills aren’t docs. They’re APIs. The description field (~100 tokens) is your function signature. The body (<2,500 tokens) is your implementation. The references/ folder is your internal package. And just like a bad function signature makes great code unreachable, a bad description makes great instructions invisible.
The agent reads all descriptions at startup, picks which skills to activate, and loads the full body only for the winners. If your signature doesn’t match the call site, your code never runs. Same problem. Same fix: design the interface first.
I maintain cc-skills-golang: 35+ Go-specific skills covering code style, security, performance, testing, observability, and more. 300k tokens total. Eval results: 97% accuracy with skills vs 54% without across 3.000+ assertions. That’s a +43 percentage point delta.
Before you write anything
Check skills.sh, SkillsMP, ClawHub, or agentskill.sh. From your terminal:
npx skills find <keyword>If a skill exists and it’s mediocre, create a new one. If nothing exists, scaffold with the skill-creator skill (it knows the Agent Skills spec so you don’t have to re-read it every time).
Design the function signature first
Three failure modes I see everywhere:
Under-triggering. Description says “Implements X using library/foo.” The agent has no idea when to use it.
# ✗ Bad → never fires
description: Implements dependency injection
# ✓ Good → fires on the right signal
description: Golang dependency injection with Google Wire. Apply when
using or adopting Wire, or when the codebase imports
`github.com/google/wire`. Not for manual DI or uber-fx.Over-triggering. “Use when writing Go code.” Congrats, you’ve wasted context on every session.
Competing triggers. Two skills claim the same keywords. The agent picks randomly. Fix: add explicit boundary disclaimers.
In cc-skills-golang, four skills cover the performance domain. They could easily collide. Instead, each owns one concern and cross-references the others:
→ golang-performance owns optimization patterns (”if X bottleneck, apply Y”)
→ golang-benchmark owns measurement methodology, profiling, benchstat
→ golang-troubleshooting owns debugging workflows, pprof setup, Delve
→ golang-observability owns always-on production signals (logs, metrics, tracing)
Each description says what it does AND what it doesn’t. “Not for measurement methodology → See samber/cc-skills-golang@golang-benchmark skill.”
Pro tip: include your language keyword in every skill description. All my skills contain “Golang” so they never accidentally fire on a Python project.
Manage the payload size
Real numbers from my repo:
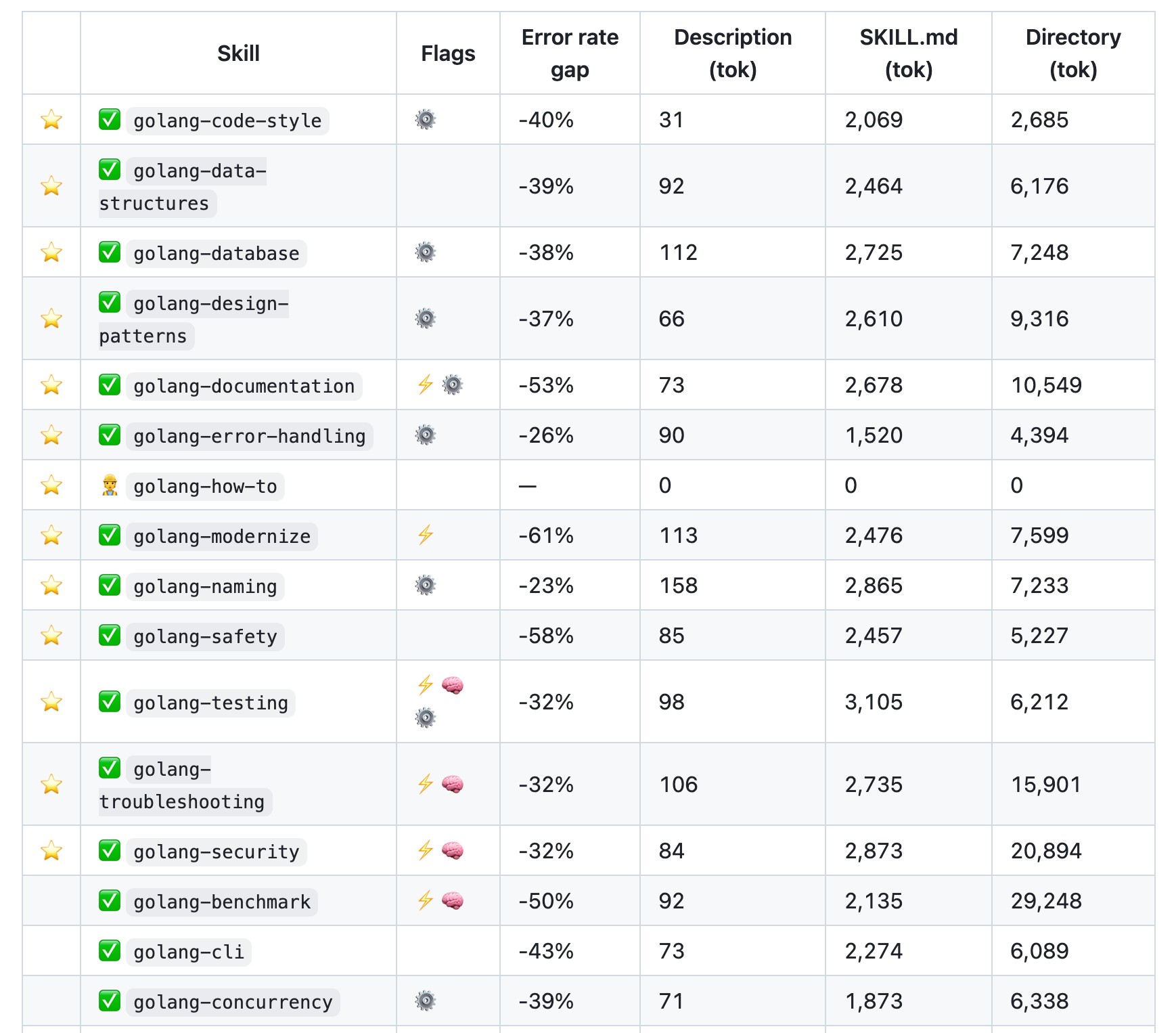
My 13 recommended ⭐️ skills load ~1.100 tokens of descriptions at startup. That’s it. Full skill content only gets pulled in when relevant.
Here’s the actual range across 35+ published skills:
→ Descriptions: 31 to 158 tokens
→ SKILL.md bodies: 788 to 3.105 tokens
→ Full directories (with references): 1.916 to 29.190 tokens
The golang-benchmark skill is 29k tokens total. But the SKILL.md itself is only 2,106 tokens. The other 27k lives in references/ and loads only when the agent needs CLI examples or profiling methodology.
Progressive disclosure is the architecture. SKILL.md is the entry point. Heavy content goes in references/. Measure with:
npx tiktoken-cli --exclude "evals" skills/your-skill/Format with Prettier first. It changes token counts.
Small interfaces, not monoliths
Every concept lives in exactly one skill. All others cross-reference using the owner/repo@skill-name format (recognized by find-skills on skills.sh).
I started with bigger skills. They always ended up getting split. golang-security at 20.894 directory tokens is one of the largest, but it’s one cohesive domain. Meanwhile golang-error-handling (4.394 tok) used to be mixed into both golang-code-style and golang-safety. Extracting it into its own skill immediately improved trigger accuracy for all three.
The cross-reference format:
samber/cc-skills-golang@golang-security # common form
samber/cc-skills-golang@golang-security:1.2.0 # pinned versionThis maps directly to install commands:
npx skills add samber/cc-skills-golang --skill golang-securityFrontmatter decisions that compound
user_invocable: false should be your default. Most skills are contextual. They auto-trigger based on what the developer is doing. Setting user_invocable: true pollutes the slash-command namespace. Reserve it for explicit actions like /security-audit or /benchmark. In my repo, only 7 out of 30+ skills are user-invocable.
allowed-tools is your permission boundary and security surface. Start from a default set:
allowed-tools: Read Edit Write Glob Grep Bash(go:*) Bash(golangci-lint:*) Bash(git:*) AgentThen add only what the skill needs. Bash(benchstat:*) for benchmark skills. Bash(dlv:*) for debugging. Bash(govulncheck:*) for security. If your skill doesn’t need web access, don’t grant WebFetch. Every extra permission is attack surface.
Company overrides. If your skill provides community defaults (naming, code style, concurrency patterns), instruct the skill to allow override. 15 of my skills use this. It’s the difference between “install and fight with it” and “install and customize.”
Top-of-body directives
The first lines after frontmatter set the agent’s frame. Three optional directives, in order:
Persona. 1-2 sentences. Primes the model’s angle.
**Persona:** You are a Go performance engineer. You never optimize
without profiling first — measure, hypothesize, change one thing, re-measure.Thinking mode. For deep analysis skills, trigger extended reasoning:
**Thinking mode:** Use `ultrathink` for profiling interpretation and
root cause analysis. Shallow reasoning produces wrong conclusions here.Four of my skills use ultrathink: golang-testing, golang-troubleshooting, golang-security, golang-benchmark. These are the ones where shallow reasoning actively hurts.
Modes. If your skill serves multiple contexts, name them. My golang-security skill has three:
→ Coding mode: sequential, optional background agent for security checks on new code
→ Review mode: sequential, traces call sites from the PR diff outward
→ Audit mode: parallel sub-agents split by concern (injection, auth, crypto, deps, input validation → up to 5 agents)
Without explicit modes, the agent might apply audit-level thoroughness to a one-line change.
Parallelism patterns
Three ways to use sub-agents:
Split by concern. Security audit launches 5 agents in parallel. Each searches for a different class of vulnerability. They may read the same file independently. That’s fine.
Split by scope. Same task, different packages. Agent 1 covers pkg/, Agent 2 covers internal/, Agent 3 covers cmd/. Useful for large repos.
Background agents. Non-blocking. Run security checks while the main agent writes code. Results surface when complete.
Don’t parallelize coding mode on a single file. Sequential is simpler and usually right. Save parallelism for audit-scope work.
Teach reasoning, not rules
# ✗ Bad — bare imperative
NEVER use math/rand for security-sensitive values.
# ✓ Good — teaches the why
math/rand output is deterministic. An attacker who knows the seed reproduces
the full sequence. Use crypto/rand for any value that must not be guessable.
**Diagnose:**
1- grep for `math/rand` imports in security-sensitive packages
2- `go vet ./...` — check for known unsafe patternsEvery recommendation needs: what goes wrong without it, how to diagnose before fixing, and a before/after when the fix isn’t obvious.
CLI reference files
When a skill mentions a tool, create references/cli-reference.md with exhaustive command examples. My golang-benchmark skill has 27k tokens of reference material. Most of it is realistic pprof, benchstat, go test -bench examples with flags, output, and interpretation.
LLMs apply tools much better after seeing 20 concrete examples than after reading an abstract description.
For library-specific skills, recommend checking docs via Context7. But watch out: Snyk’s Agent Scanner flags explicit MCP tool-calling instructions as prompt injection. Don’t write “call resolve-library-id“ in your body. Instead:
This documentation is not exhaustive. Please refer to library documentation
and code examples. Context7 can help as a discoverability platform.You can still list mcp__context7__* in your allowed-tools frontmatter. Only body text triggers the scanner.
Evaluation: adversarial or useless
If your eval passes 100% both with and without the skill, you’re testing common knowledge. Either your eval or your skill is worthless.
Good evals have traps. My golang-samber-do skill (dependency injection) has a -81% error rate gap. Without the skill, the agent writes NewStore() constructors manually. With the skill, it uses the DI container correctly. The eval never mentions samber/do by name. It just asks for “a service with lazy initialization and health checks.” The skill steers the agent. The eval measures whether it worked.
Anti-patterns to avoid:
→ Testing strings.Builder when the task obviously needs string building. The model knows this without your skill.
→ Testing make([]T, 0, n) when preallocation is obvious. The model knows this too.
→ Any eval where both with/without score 100%. Redesign it.
The trick: frame your eval so the natural approach is wrong. If the skill teaches “use container/heap for priority queues with dynamic priority updates,” the eval asks for “an LRU cache with TTL eviction.” Don’t mention container/heap. Don’t hint. Measure whether the skill steers the agent away from the naive sorted-slice approach.
Sizing rule: ~10 assertions per 1,000 tokens of skill content.
Process:
Design traps. Frame tasks so the default approach is wrong.
Clear agent session. Load ONLY
skill-creator+ skill under test.Never load sibling skills. They leak overlapping guidance and inflate the “without” score.
First run: human-as-judge (validate scenarios are actually adversarial).
Follow-ups: LLM-as-judge for iteration speed.
Record everything in
EVALUATIONS.md. Track with/without scores and delta.
My overall: 2823/2895 (97%) with vs 1574/2895 (54%) without. The +43pp delta tells me the skills add real value. Individual skills range from -23% (golang-naming) to -81% (golang-samber-do).
Distribute everywhere
A skill in your .claude/skills/ helps one person. Publishing it helps thousands.
skills.sh (Vercel). The leaderboard. npx skills add samber/cc-skills-golang. Snyk integration for security scanning.
ClawHub (OpenClaw). Vector search, versioning, changelogs. clawhub install <path>. Security analysis per skill.
SkillsMP. Auto-scrapes GitHub. If your repo has SKILL.md files, you’re already indexed.
Claude Code plugin. Add .claude-plugin/plugin.json. Users install with /plugin marketplace add samber/cc. Also create .cursor-plugin/plugin.json and gemini-extension.json. Keep versions synchronized across all three manifests.
Cross-platform installs. My repo works on Claude Code, Cursor, Copilot, Codex, Gemini CLI, OpenCode, OpenClaw, and Antigravity. Same skills, different install paths. The README has one-liners for each.
Run Snyk Agent Scanner before publishing:
bash
uvx snyk-agent-scan@latest --skills ./skills/Snyk’s ToxicSkills research scanned ~4,000 skills. 36% had prompt injection issues. 76 confirmed malicious payloads for credential theft and data exfiltration. Don’t be in that list.
Override convention
Some skills are community defaults, not mandates. If a company has internal conventions, they should win.
My overridable skills (marked ⚙️) include a note at the top:
If a company-specific skill supersedes this one, defer to it.And the company skill says:
This skill supersedes `samber/cc-skills-golang@golang-naming`
for [Company] projects.15 of my 35+ skills support this. It makes adoption in teams much smoother: install the community defaults, override only what your team disagrees with.
What I’d do differently
→ Write descriptions first, bodies second. The description is the interface. Get it right before investing 2.500 tokens.
→ Measure token counts on every commit, not as an afterthought. Use npx tiktoken-cli in CI if you can.
→ Invest in the eval harness on day one. Skills with adversarial evals improved fastest. Skills without evals drifted. Then iterate with LLM-as-judge eval.
→ Split skills earlier. Every monolith eventually becomes two or three atomic skills. Start atomic and merge if needed (you won’t need to).
→ Obsess less about individual skills, more about the cross-reference graph. A skill ecosystem is a graph, not a list. The connections between skills matter more than any single node.
→ Version everything. SKILL.md version, plugin version in .claude-plugin/plugin.json, .cursor-plugin/plugin.json, gemini-extension.json. All must stay in sync. I learned this the hard way.
→ For non-technical skills, generate the first version on claude.ai with deep research enabled. The agent will search the best-in-class articles on the matter.
What’s your biggest pain point building skills? What patterns am I missing? Reply or comment.
If you enjoy my work, consider sponsoring me on GitHub. Your support helps me keep writing and creating open-source projects 👉 github.com/sponsors/samber